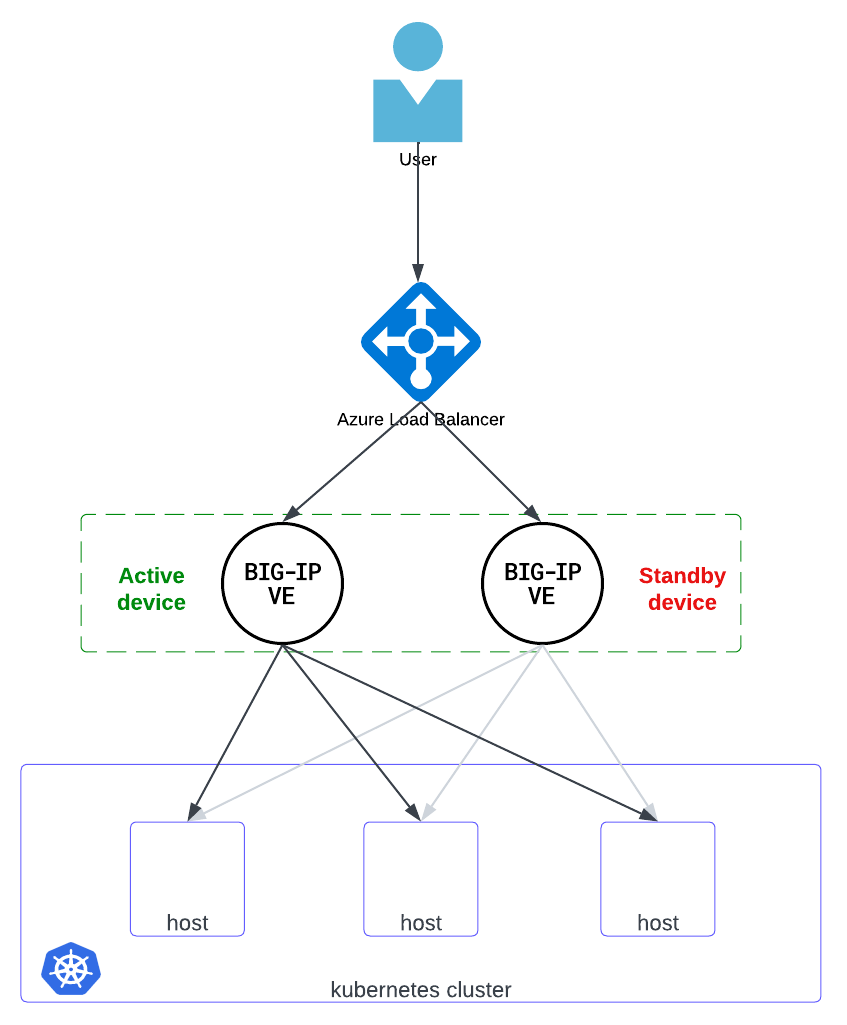
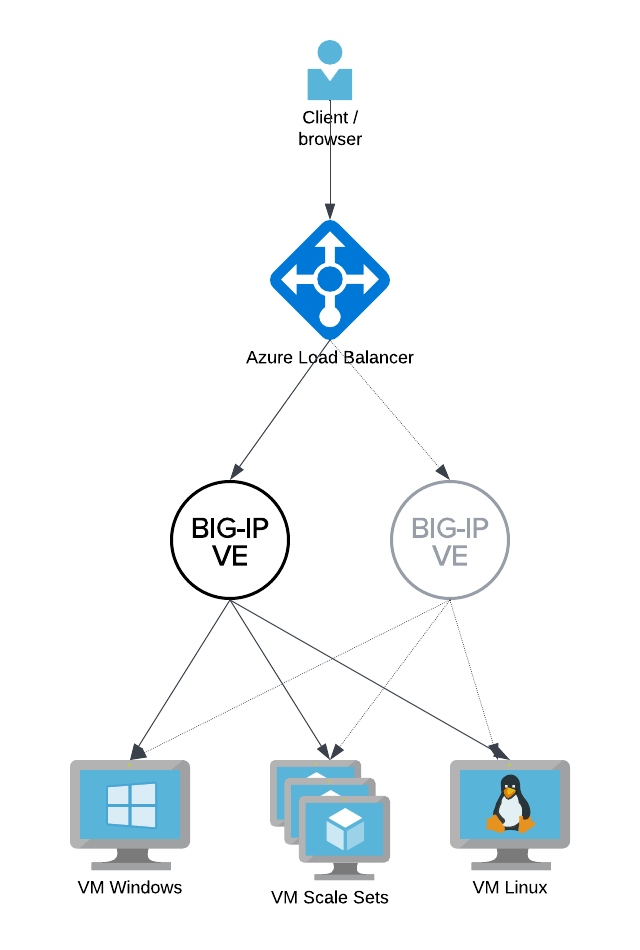
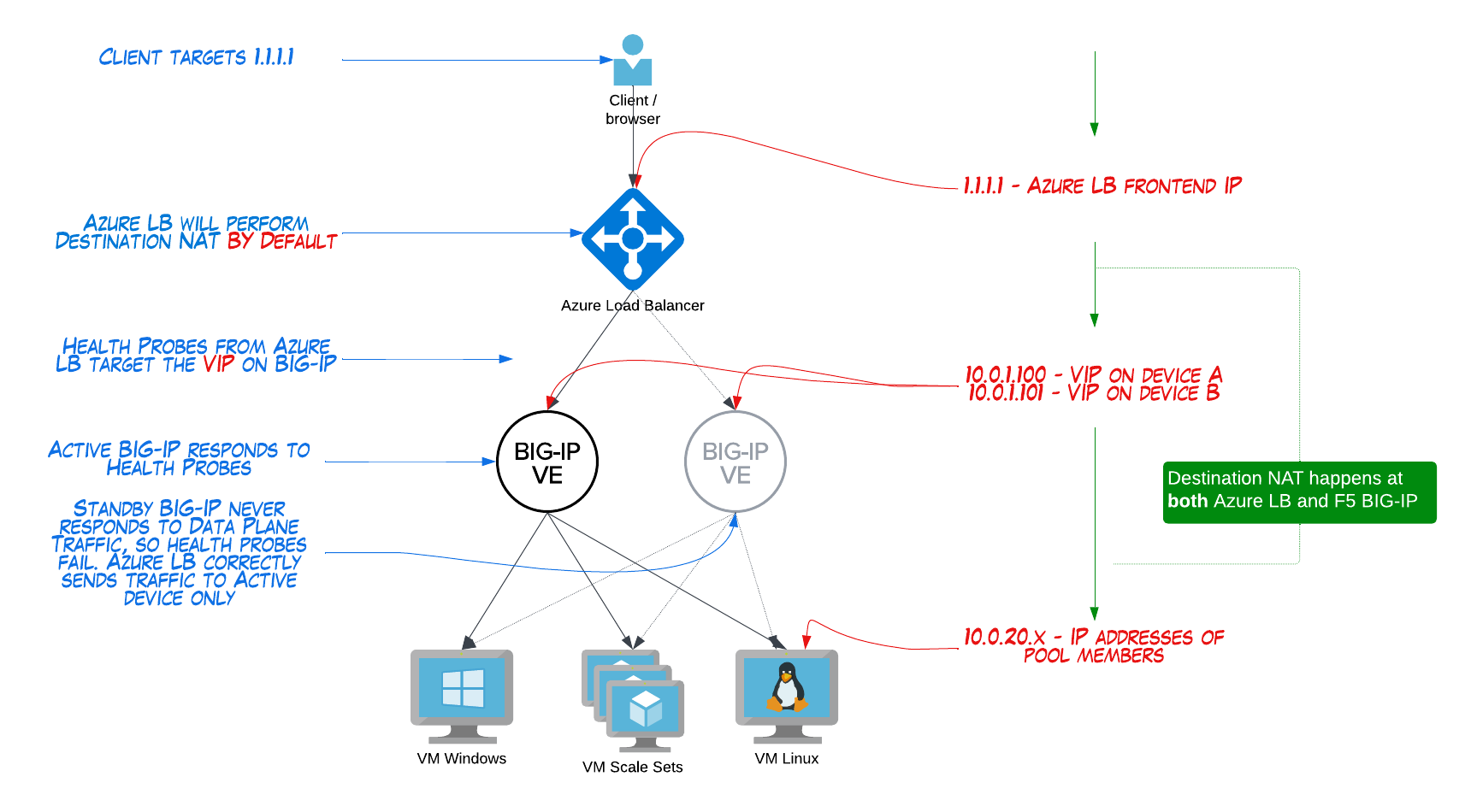
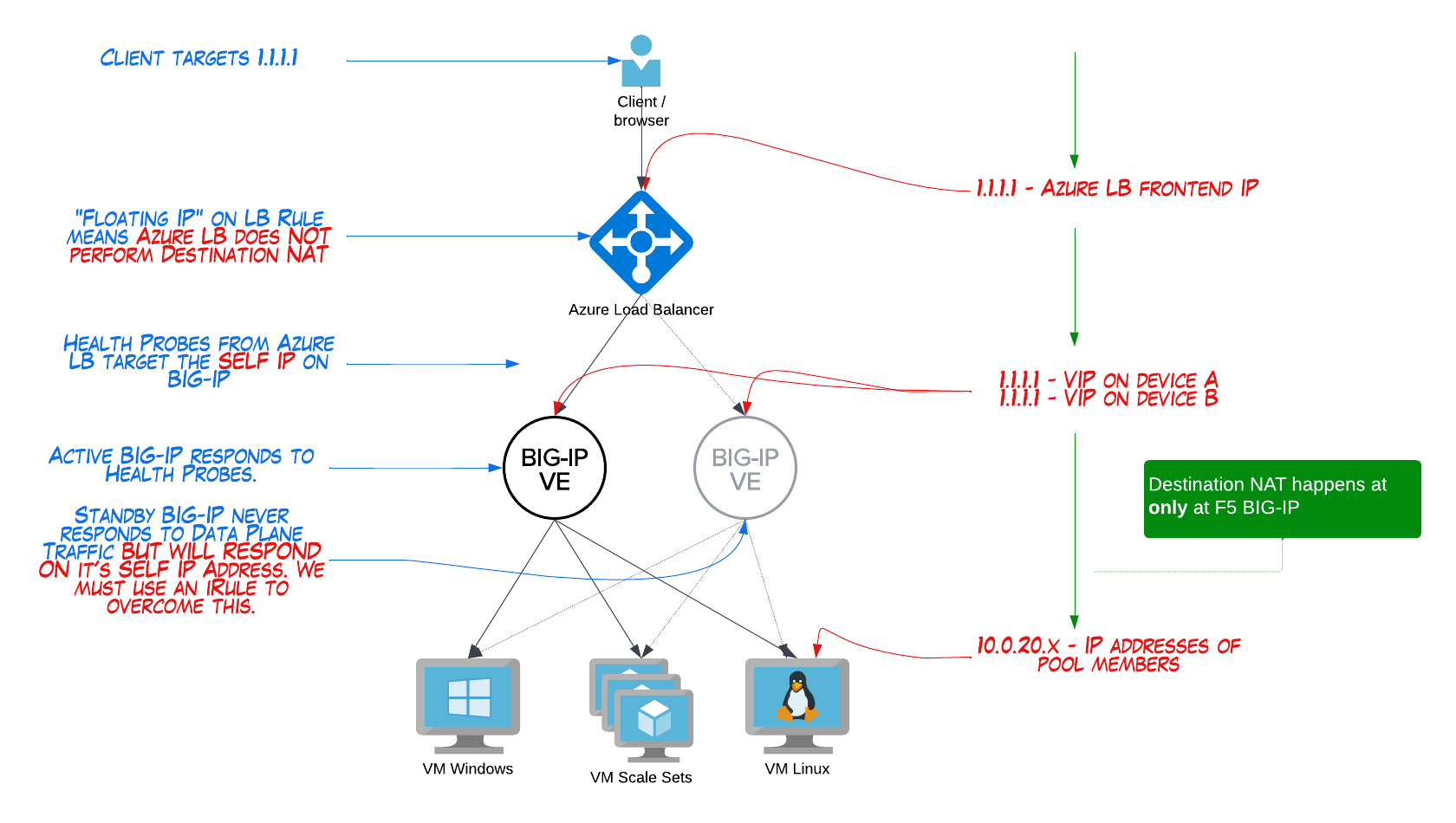
- Azure Load Balancer
- Cloud Failover Extension (CFE)
- DNS-based HA
There are further options. The Azure GWLB is an option, but I’ll consider this another load balancer option in category 1. And the CFE approach has some further sub-options too. You can move public or private IP addresses between devices (just like ARP does on-prem), or update UDR in Azure with a CIDR block that covers the entire VIP range.
I will offer an additional alternative:
- BGP and Azure Route Server
This article covers the concept and how-to of using BGP for High Availability in Azure. Using BGP and Route Health Injection with F5 is nothing new, but it is almost never seen in public cloud environments. Still, some methods that have been used for many years on-prem (Route Health Injection, or Active/Active with ECMP) can be achieved in Azure, using Azure Route Server.
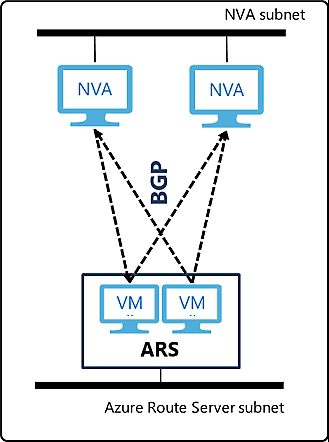
HA using Azure Route Server
I’ll cover some concepts that are related but discussed separately: Route Health Injection for Virtual Servers, and more generic BGP route advertising. I’ll also talk about Active/Standby vs Active/Active options, and ECMP.
I will then outline multiple methods and a “how-to” for achieving HA in Azure using BGP routing:
- Active/Standby (Routing to Active device only)
- Active/Active routes for multiple BIG-IP devices, using the network command or static routes
Concepts: Active/Standby vs Active/Active
Route Health Injection and Active/Standby mode
Route Health Injection allows the BIG-IP to advertise VIPs via routing protocols. As a basic example, a VirtualServer may have an IP address of 192.168.100.100/32. BIG-IP can advertise this /32 route to peers based on the health of the Virtual Server. Another example: I could have a VIP with a destination IP of 192.168.100.0/24, and then this route would also be advertised with a next hop of BIG-IP.
In an Active/Standby device group, both devices are sharing routes via BGP with the Active device as the next hop. In a graceful failover, both devices will immediately update their neighbors with the next hop of the (newly) Active BIG-IP. If the failover is not graceful and the Active device is suddenly lost, it’s BGP peering will be broken and its neighbors will remove the routes that were learned from the device that was Active but is now offline.
When considering an Active/Standby device cluster, let’s highlight words from F5’s guidance on dynamic routing:
Note: When you configure RHI in a device group configuration, only devices with active traffic groups attempt to advertise routes to virtual addresses.
BGP configurations and Active/Active mode
In an Active/Active scenario, multiple devices can advertise a route with equal weight. To ensure traffic flow is symmetric, neighbor routers must support ECMP (this ensures that a connection from a client is persisted to a single BIG-IP only). Azure Route Server uses ECMP when multiple devices advertise the same route with the same AS path length.
There are several methods by which you can share routes via BGP from BIG-IP, whether the device is Active or Standby. Using these methods will result in the same route and AS path with multiple next hops: ie., Active/Active routes on BGP peers.
How-to: HA with BIG-IP using Azure Route Server
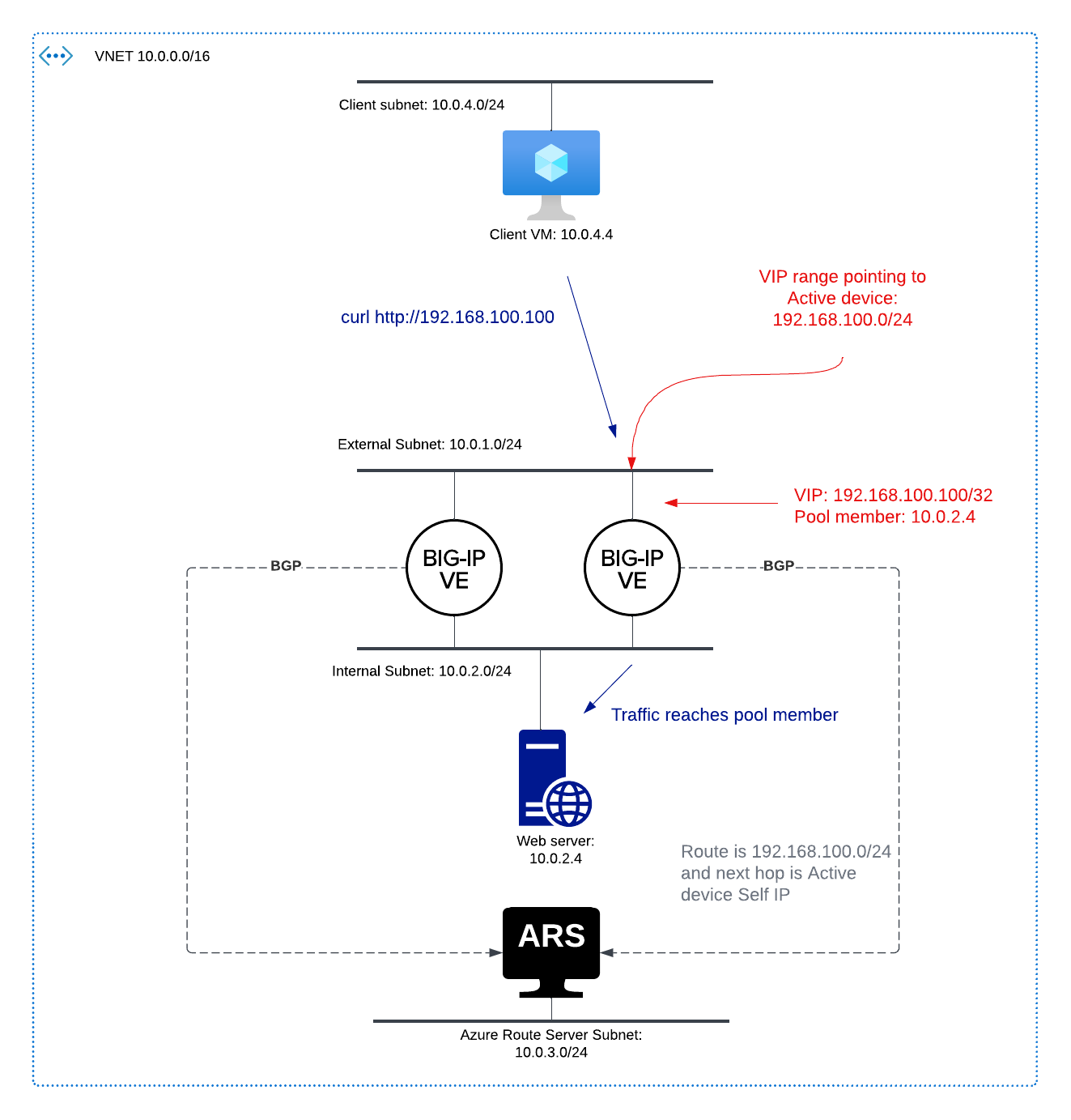
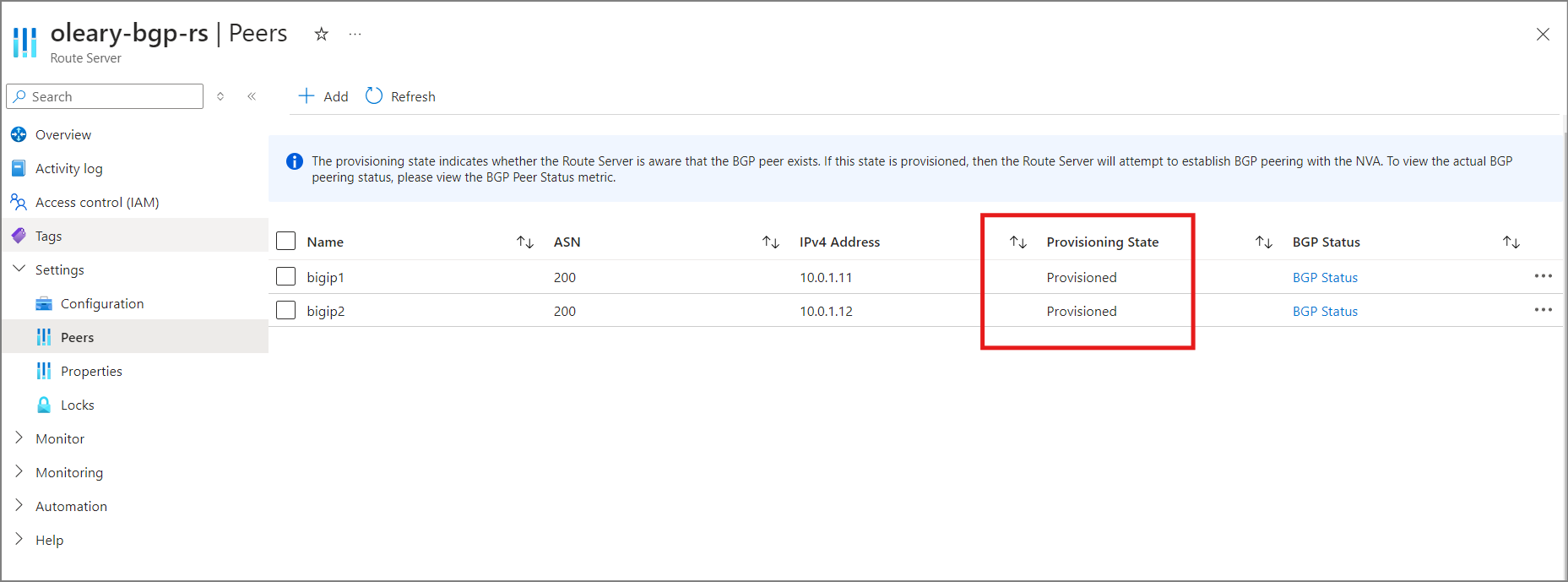
Whether we will choose an Active/Standby or Active/Active approach, we must first set up BGP peering between F5 BIG-IP and Azure Route Server. These instructions assume we have a single BIG-IP HA pair in Azure and are configuring iBGP peering between our BIG-IP devices and eBGP peering with Azure Route Server.
- Follow this tutorial from Microsoft on configuring Azure Route Server. Configure only Azure Route Server. Stop when you reach this section for configuring a network virtual appliance (NVA). We’ll use F5’s instructions to configure BIG-IP devices instead.
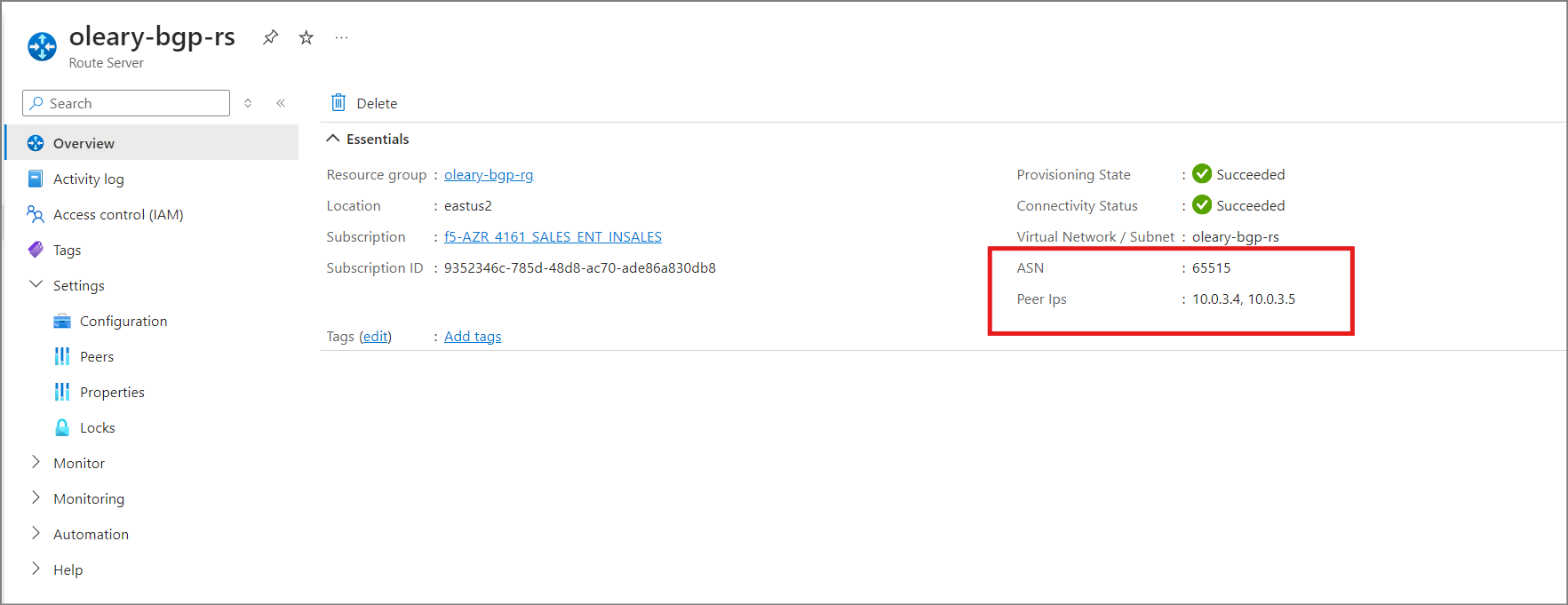
Take note of the ASN and Peer IPs after the Route Server is created. The ASN will always be 65515. We will use this, and the Peer IP’s, when configuring BGP on BIG-IP.
- Follow this tutorial from F5 on configuring BGP on BIG-IP.
- allow TCP/179 on appropriate Self IPs.
- enable BGP on your Route Domain:
tmsh modify /net route-domain 0 routing-protocol add { BGP } - configure iBGP between your BIG-IP devices. This script will be slightly different on each device.
1 2 3 4 5 6 7 8 9 10 11
# run these commands on both devices. The "neighbor" commands will be unique on each device. imish enable config terminal router bgp 200 neighbor 10.0.1.12 remote-as 200 # neighbor 10.1.1.11 remote-as 200 neighbor 10.0.1.12 activate # neighbor 10.0.1.11 activate end write
- configure eBGP between the devices and the Azure Route Server. This script will be identical on each device.
- notice that a route map is created in order to filter which routes we share via BGP (only 192.168.100.0/24)
- notice the “redistribute kernel” command, without which, BGP would not share Kernel routes (and would share routes that we could configure manually using imish commands)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
imish enable config terminal ip prefix-list PFX_ALLOW_VIPS seq 5 permit 192.168.100.0/24 route-map RESTRICT_ADVERTISE permit 10 match ip address prefix-list PFX_ALLOW_VIPS router bgp 200 redistribute kernel neighbor 10.0.3.4 remote-as 65515 neighbor 10.0.3.5 remote-as 65515 neighbor 10.0.3.4 activate neighbor 10.0.3.5 activate neighbor 10.0.3.4 route-map RESTRICT_ADVERTISE out neighbor 10.0.3.5 route-map RESTRICT_ADVERTISE out end write
- Return to Microsoft’s tutorial at this location to configure Route Server peering.
- create a peering to BIG-IP device 1
- create a peering to BIG-IP device 2
Ideally, at this point the Status of the Peering will show completed. Lastly, don’t forget to check the box “enable IP Forwarding” on your NIC in Azure if you want to use a VIP range that is not native to your VNET.
- We can check learned routes from the Azure Route Server. The Microsoft tutorial uses PowerShell and the Get-AzRouteServerPeerLearnedRoute cmdlet. I prefer az cli so I’ll use:
1
2
3
4
5
$ az network routeserver peering list-learned-routes -g oleary-bgp-rg --routeserver oleary-bgp-rs -n bigip1
{
"RouteServiceRole_IN_0": [],
"RouteServiceRole_IN_1": []
}
Important
We should ensure that we only share routes with Azure Route Server that we intend to share. Typically we do not want to advertise the 0.0.0.0/0 route from the BIG-IP, because it will cause the entire VNET’s default route to be BIG-IP (and likely make your VNET unreachable). For that reason, we’ve created a route map that will filter any shared routes and only allow our desired route, 192.168.100.0/24, to be advertised via BGP.
At this point, Azure Route Server has not received any routes from BIG-IP, but the BGP relationship is Established.
1. Active/Standby: Advertising a VIP range from the Active device only
In this example, I’ll use a range (192.168.0.0/24) for my VIPs. In the cloud, I’ll often call this an “alien range” because it will be a CIDR block that does not truly exist in the VNET or VPC, but that is routed toward the BIG-IP.
-
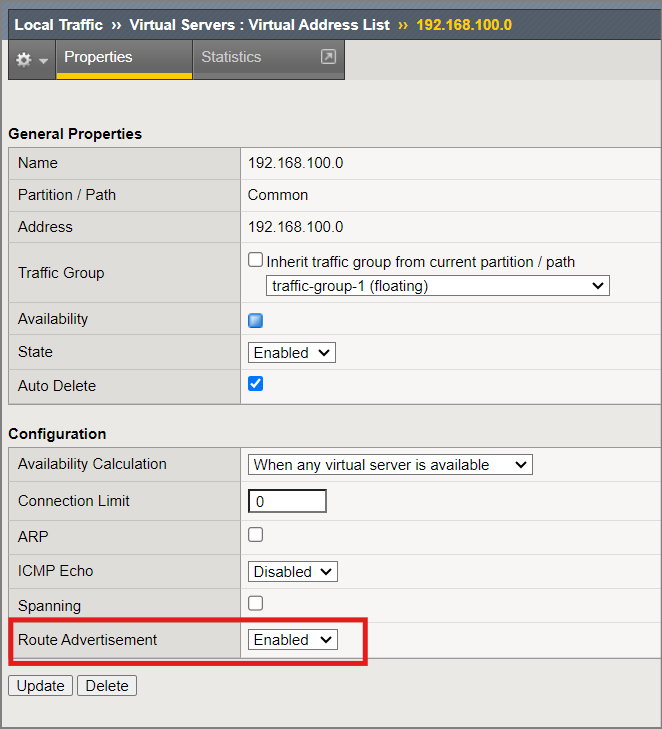
Create a “dummy” VIP where the Destination IP is 192.168.100.0/24. We won’t actually target this VIP, so it can be any type (eg IP forwarding).
-
Set the Virtual Address to have “Route Advertisement” set to “Enabled”.
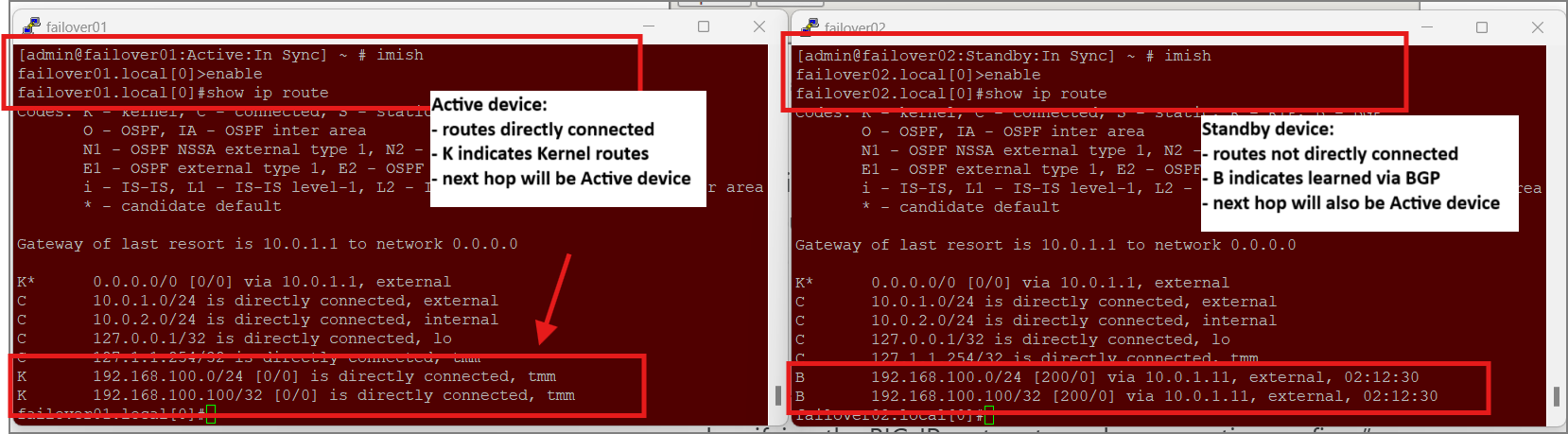
This VIP will be “redistributed” by BGP because it matches our allowed route for BGP sharing. It will be advertised with a next hop of the Active BIG-IP device. Let’s check this from both our Active and Standby device, and see that
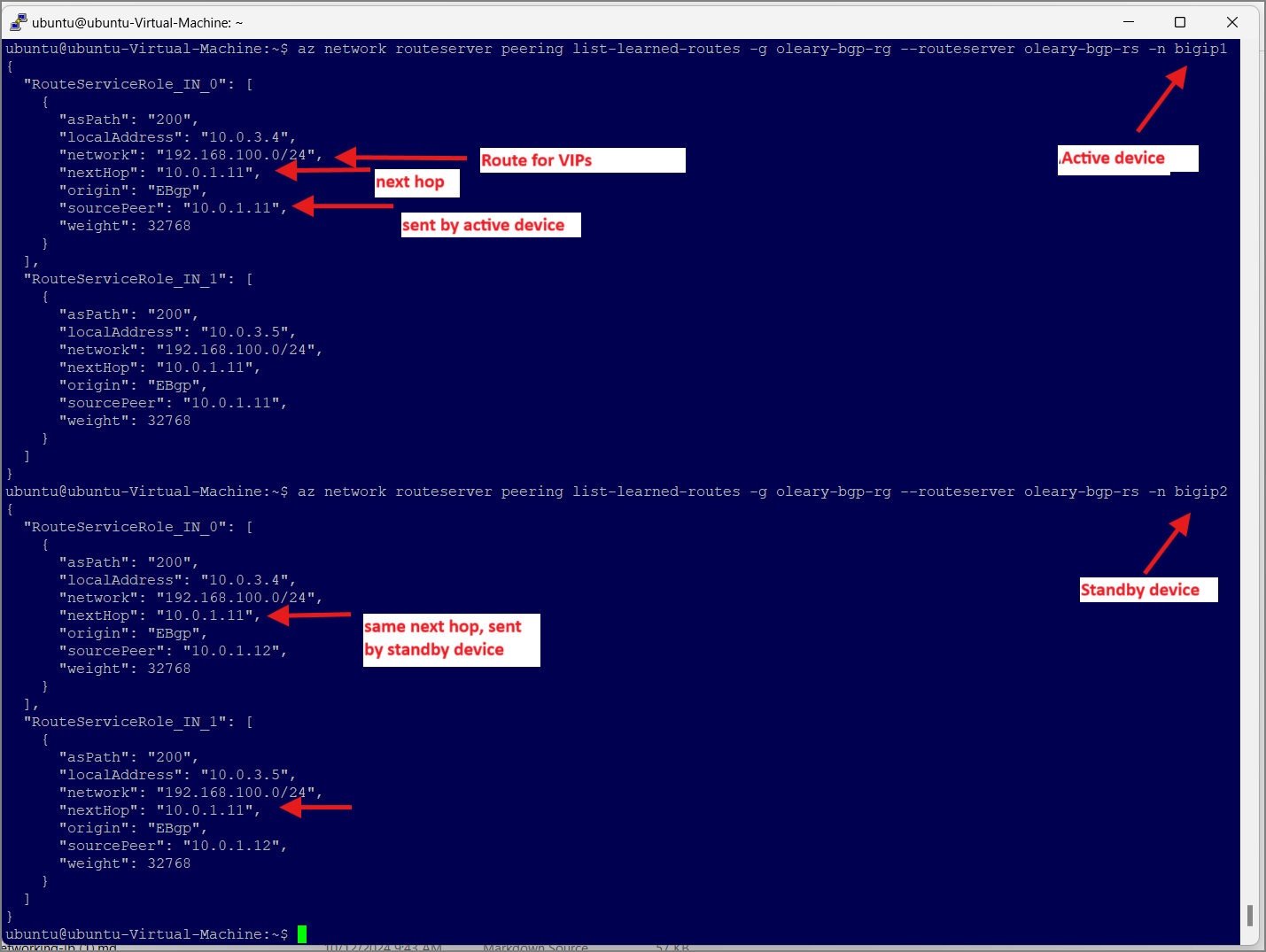
We can also check the Azure Portal (eg, the effective routes of interfaces in the VNET) or use the CLI commands from earlier to see the learned routes by Azure Route Server.
2. Active/Active: using BGP to advertise routes from both devices
Let’s return to the section of our F5 tutorial titled “Configuring and verifying the BIG-IP system to exchange routing prefixes”.
You can exchange network prefixes with BGP on the BIG-IP system with the network command or through redistribution. Using these methods will likely result in both your Active and Standby devices advertising a route with their own Self IP as the next hop.
- To use the network command to manually configure a route to advertise, you would use imish configuration like this:
1
2
3
4
5
6
7
imish
enable
configure terminal
router bgp 200
network 192.168.100.0/24
end
write
You also would not need to advertise kernel routes in this scenario, so you could add no redistribute kernel if so desired.
Use the same methods as above to verify learned routes in Azure. You can also use show ip bgp neighbor 10.0.3.4 advertised-routes to verify which routes are advertised to Azure from the perspective of BIG-IP.
- Another option is to create static routes on BIG-IP itself - with GUI or
tmsh create net route- and share those. However, network routes in BIG-IP cannot have a Self IP as the next hop, so sharing these routes will not result in routes in Azure’s VNET that point to BIG-IP. In this case, I don’t see a good reason to explore this option further.
Other Considerations
BGP offers some advantes. No Azure load balancer is required in this design. Unlike CFE, there are no Managed Identities to configure, no RBAC permissions, and no API calls needed from BIG-IP to Azure’s management plane.
However, peering with BGP requires the Advanced Routing module (included with Better and Best licenses) and Azure Route Server. BGP also requires planning, skills, and perhaps team cooperation beyond what may have been planned.
Some BIG-IP admins have strong network skills and feel comfortable with BGP; others may fear the potential to cause outages beyond just BIG-IP if misconfigured.
Conclusion
Failover via BGP and Azure Route Server is fast and reliable, although personally I see Azure Load Balancer and CFE implementations much more commonly. Thanks for reading and please reach out with any questions!