Deploying OpenShift with metal nodes
Summary
In order to use OpenShift Virtualization, your nodes must support virtualization. If you’re running OpenShift in AWS, as I like to do when I deploy in a hurry, you will need to use bare metal nodes. That is very expensive, but cost can be reduced if you build a small cluster first and then add a single metal node for a small and quick PoC.
Deploying OpenShift
I do not claim expertise in OpenShift, but as a popular enterprise tool I need to be aware and capable with OpenShift. I’m considering OpenShift certification in future for this reason.
As I’ve written before, I typically deploy OpenShift in AWS, using the installer command line tool. This is Installer Provisioned Infrastructure (IPI), where the CLI tools builds my EC2 instances (they don’t pre-exist and I don’t have to build them myself.)
As you can see from my default install-config.yaml file, I will deploy 3 master nodes and 3 worker nodes. You can change worker nodes to 2 if you want to save a little more money.
KubeVirt and OpenShift Virtualization
I’m late to the game and learning about running VM’s on OpenShift, which requires that the node supports virtualization. Since the AWS EC2 instances do not, the solution is to deploy a cluster with metal nodes. But that is very expensive.
The answer is to use machinesets in OpenShift. Specifically, I found this nice article that spoke about OpenShift Virtualization on AWS, and how to reduce the cost of a PoC: deploy a cluster with regular EC2 instances and then an additional single bare metal node. Then remember to kill that metal node as soon as you’re done!
How to PoC OpenShift Virtualization in AWS
I’ll document my steps here so I can remember for future:
- Deploy OpenShift cluster. You can scale back to 2x worker nodes (+3 master = 5 nodes total in the cluster.)
.\openshift-installer create cluster --dir=cluster --log-level=debug
- After cluster is built, I personally see 2x machinesets when I get all machinesets:
(I have transposed the cluster id suffix with x’s)
1
2
3
4
5
$ oc get machinesets -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
ocpcluster-xxxxx-worker-us-east-1a 1 1 1 1 27m
ocpcluster-xxxxx-worker-us-east-1b 1 1 1 1 27m
I also see my VM’s in the EC2 console:
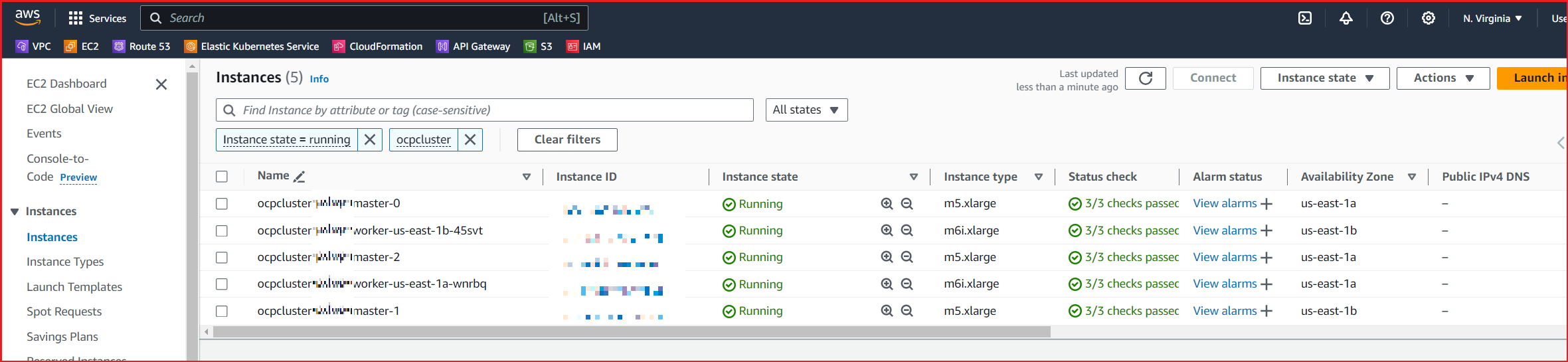
- Then I follow the instructions in the article to create a new machineset by editing an existing machineset.
oc get machinesets -n openshift-machine-api ocpcluster-xxxxx-worker-us-east-1a -o yaml > machineset.yaml
After editing machineset.yaml, mine looks like this file. I apply the file, and a new machineset exists in Openshift (see the last in the list, with desired=0)
1
2
3
4
5
6
7
8
$ oc apply -f machineset.yaml
machineset.machine.openshift.io/ocpcluster-xxxxx-worker-us-east-1c created
$ oc get machineset -n openshift-machine-api
NAME DESIRED CURRENT READY AVAILABLE AGE
ocpcluster-xxxxx-worker-us-east-1a 1 1 1 1 32m
ocpcluster-xxxxx-worker-us-east-1b 1 1 1 1 32m
ocpcluster-xxxxx-worker-us-east-1c 0 0 19s
- I then scale this machineset to 1, and sure enough a metal VM is built in AWS.
1
2
$ oc scale machineset ocpcluster-xxxxx-worker-us-east-1c -n openshift-machine-api --replicas=1
machineset.machine.openshift.io/ocpcluster-xxxxx-worker-us-east-1c scaled
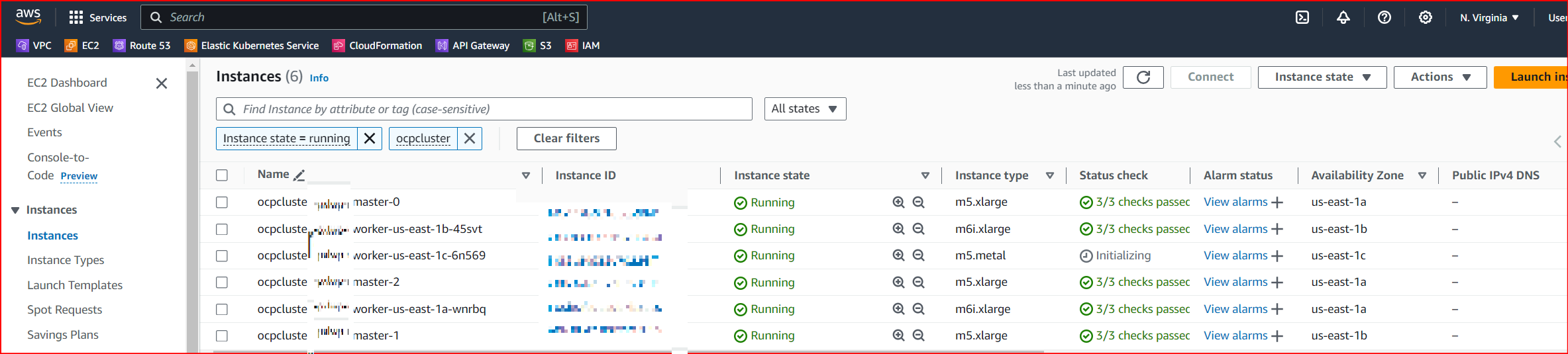
- At first, the new EC2 instance is in a Provisioning state, but is not yet a node in OpenShift. A good 15 mins or so later, that metal VM is both a machine and a node.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
### After applying the file:
$ oc get machines -n openshift-machine-api
NAME PHASE TYPE REGION ZONE AGE
ocpcluster-xxxxx-master-0 Running m5.xlarge us-east-1 us-east-1a 41m
ocpcluster-xxxxx-master-1 Running m5.xlarge us-east-1 us-east-1b 41m
ocpcluster-xxxxx-master-2 Running m5.xlarge us-east-1 us-east-1a 41m
ocpcluster-xxxxx-worker-us-east-1a-wnrbq Running m6i.xlarge us-east-1 us-east-1a 37m
ocpcluster-xxxxx-worker-us-east-1b-45svt Running m6i.xlarge us-east-1 us-east-1b 37m
ocpcluster-xxxxx-worker-us-east-1c-6n569 Provisioned m5.metal us-east-1 us-east-1c 9m3s
$ oc get nodes
NAME STATUS ROLES AGE VERSION
ip-10-0-128-9.ec2.internal Ready worker 34m v1.29.7+4510e9c
ip-10-0-136-153.ec2.internal Ready control-plane,master 41m v1.29.7+4510e9c
ip-10-0-143-152.ec2.internal Ready control-plane,master 41m v1.29.7+4510e9c
ip-10-0-144-135.ec2.internal Ready control-plane,master 41m v1.29.7+4510e9c
ip-10-0-155-171.ec2.internal Ready worker 33m v1.29.7+4510e9c
### Notice that there are 6x provisioned machines, but 5x nodes. 1 of the machines is still being set up.
### After 15 mins or so, this machine will also be listed as a node. The bare metal instance must power up and then join the cluster as a node.
- I can now follow other documentation to insall OpenShift Virtualization, and then continue back in our original article for instructions to deploy Fedora.
You should now have a VM running in OpenShift.
Accessing the VM
You will notice that accessing the VM is possible using virtctl, which is a tool you will need to download.
Documentation links:
You could also create a Service (ClusterIP, NodePort, or LB) but since I haven’t done this yet, I’ll leave it for another blog post.
Thanks for reading!